Apache Kafka in 10 minutes
Aug 15, 2020
A simple overview
Kafka was developed by LinkedIn and made open source in 2011. Kafka is essentially a publish/subscribe messaging. This means that somehow, things are getting published from multiple sources, and people who want certain kinds of data can subscribe to their relevant data.
Its quite similar to Message queues with the advantage being that you can now use a single pipeline for all your message queues. Another advantage is that it can horizontally scale easily, because of the fact that you can distribute your incoming load and outgoing load. But more on that later.
Messages, Publishers and Recievers
Publisher sends messages.
Reciever subscribes to a certain set of messages.
Core of kafka are the messages. These messages are persisted which means that multiple people/’receivers’ can read the same messages. Messages are stored as byte arrays, no schema is enforced. It would be advisable to use a schema though.
How are messages recieved by Kafka?
Messages are categorized by the publisher itself into topics. Each topic is logically different. For example, one could be messages from your web app and the other could be messages from your mobile app. They are a logical segregation.
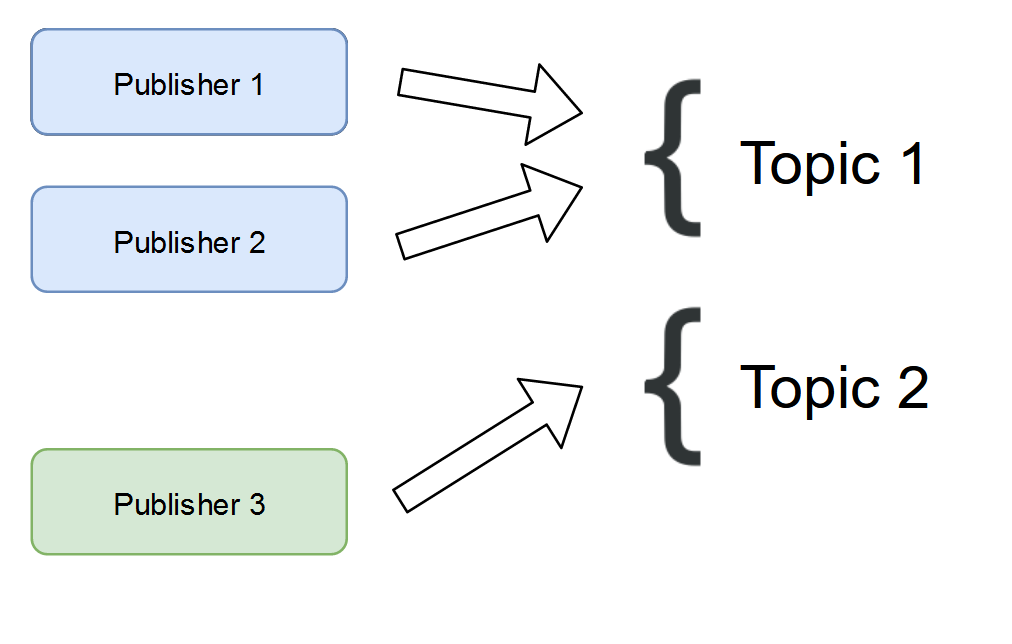
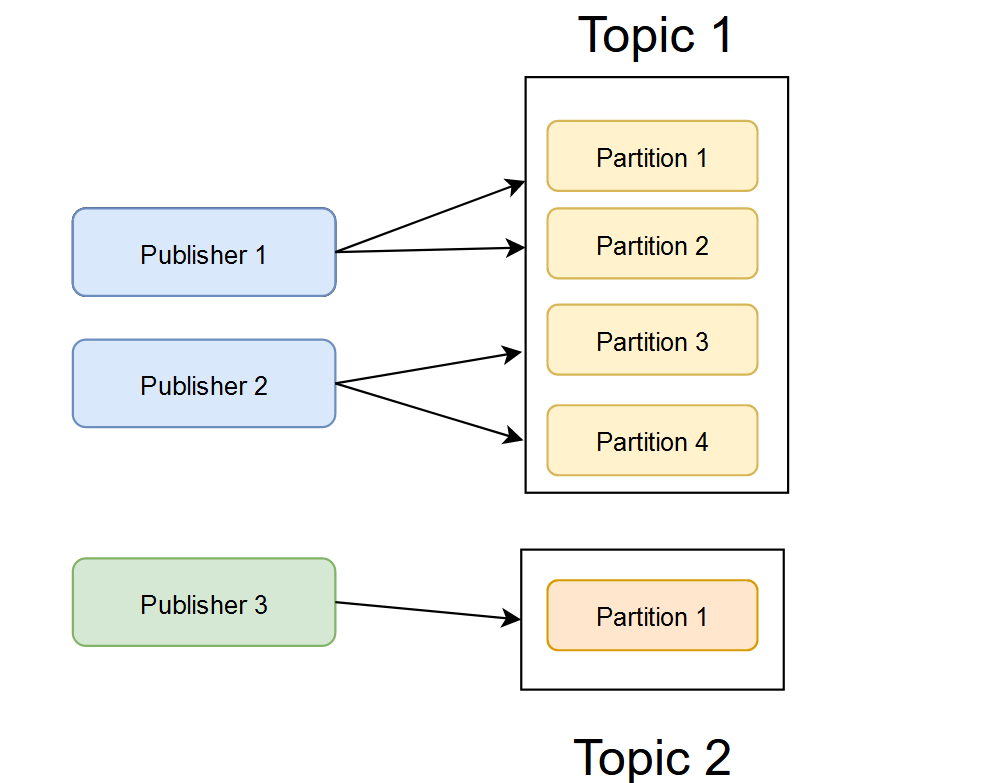
Each topic is now broken into partitions. Similar to database sharding, this is Kafka’s way of parallelizing. Each partition can be placed on a different machine and allow multiple consumers to read from the topic at the same time. Each message that is added to the partition is given an offset, similar to an index, it’s an incrementing value.
Each incoming message can be uniquely identified by the Topic, Partition, & Offset.
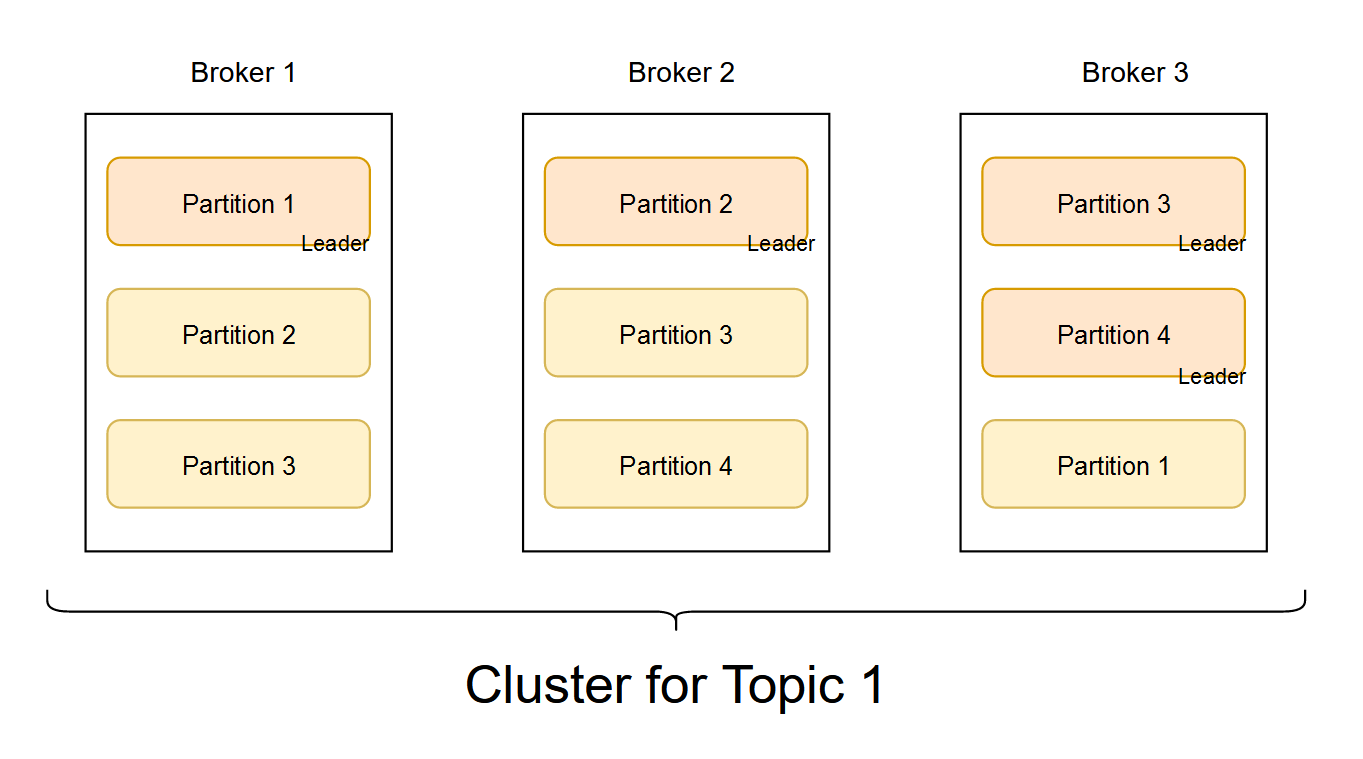
Internal Structuring of Kafka: Brokers & Clusters
Each Kafka server becomes a broker. Kafka brokers come together and form clusters. The Cluster controller controls the cluster. He takes care of the brokers and takes care of broker failures. An important part of a cluster is the replication of partitions.
When a partition is replicated, all replicated partitions have the same order of messages. Replication is done to prevent data loss incase of failure. All replicated partitions have a leader who takes the incoming messages. Once a new message is received, the leader passes this message to all other brokers who have replicated partitions.
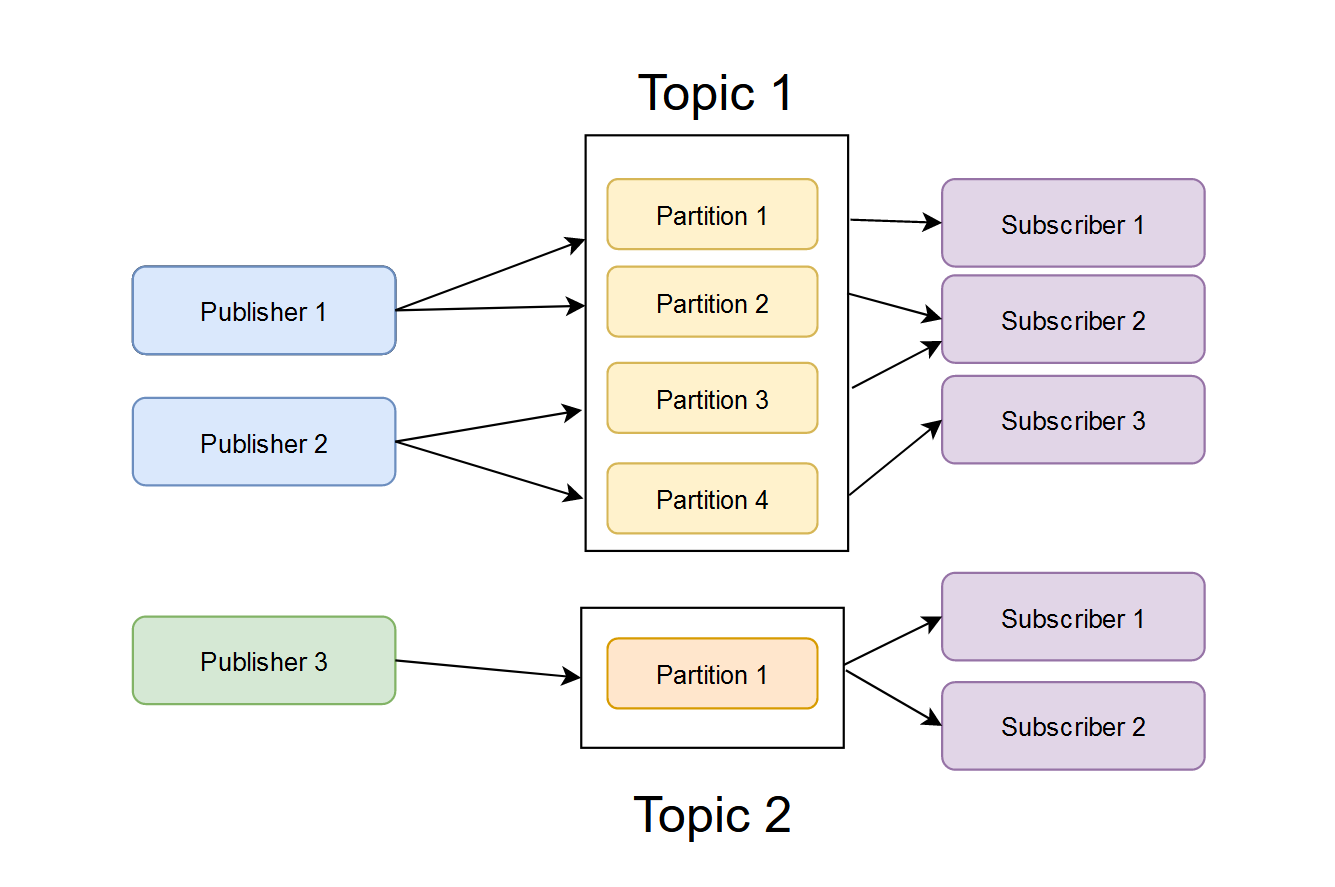
How are messages recieved from Kafka?
Consumers now read from partitions. A consumer group is a set of consumers who completely consume the messages of a topic. Consumer to partition mapping is called ownership. In a similar manner, consumers can also be horizontally scaled now. If a consumer fails, another can pick up where the previous left off.
Power of Kafka
- Multiple Publishers: It can handle a variety of messages from many different publishers.
- Multiple Consumers: Many consumers can parallely compute from the data.
- Highly Scalable: The whole system is highly scalable and only requires adding more brokers.
- Data Persistance: The data is persisted for later use, or if there is input/output mismatch between publishers and consumers.